Сбор и анализ логов samba в ELK Stack
Продолжаю тему настройки и использования централизованной системы сбора логов на основе elasticsearch. Сегодня расскажу, как настроить сбор и анализ логов аудита samba в ELK Stack. Я буду не только собирать логи, но и обрабатывать их и добавлять метаданные для построения графиков и дашбордов.
Для установки и настройки файлового сервера samba можно воспользоваться одной из моих статей:
Дальнейшее описание подойдет для обоих случаев. И для интеграции с AD, и для одиночного сервера с авторизацией по IP или имени пользователя.
Для того, чтобы samba записывала в лог все операции с файлами, необходимо настроить логирование. Как это сделать я рассказал уже давно в отдельной статье — настройка логов доступа в samba. Дальше в статье я буду считать, что у вас настроено примерно так же. Формат логов очень важен, так как ниже я предложу свой вариант grok фильтра для парсинга.
Сбор логов samba
Для сбора логов с samba сервера необходимо на него установить filebeat. Как это сделать рассказано в моей статье по установке и настройке elk stack. Создаем простой конфиг для filebeat — /etc/filebeat/filebeat.yml.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/samba/audit.log
fields:
type: smb-audit
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts: ["10.1.4.114:5044"]Минимум опций. Просто отправляем все записи лога самбы audit.log в logstash по адресу 10.1.4.114 и устанавливаем тип — smb-audit. Это сделано для удобства в дальнейшей обработке и вычленении логов самбы из общего потока данных. Идентичные настройки будут на всех серверах samba.
Парсинг логов samba в logstash
Нам нужно принять логи с samba в logstash, обработать их и передать в elasticsearch. Для приема логов в конфиге logstash /etc/logstash/conf.d/input.conf (напомню, что у меня для удобства конфиг разделен на 3 части input.conf, filter.conf, output.conf) у меня уже есть строки:
input {
beats {
port => 5044
}
}Так что ничего добавлять не надо. Дальше нам нужно настроить фильтрацию логов. Для этого в filter.conf добавляю строки:
else if [type] == "smb-audit" {
mutate {
gsub => ["message","[\\|]",":"]
gsub => ["message"," "," "]
}
grok {
match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"]
overwrite => [ "message" ]
}
}В данном случае выше в конфиге у меня уже есть другие правила. Если же данное правило у вас будет единственным, то else не нужно указывать. Расскажу, что делают данные правила. Плагин mutate и операция gsub в первой строке заменяет в логе самбы все обратные слеши \ и | на : Это сделано для того, чтобы потом было проще использовать фильтр grok. Вторая операция gsub заменяет двойной пробел на единичный. Это сделано для того, чтобы убрать двойной пробел в логах самбы, когда в числе месяца используется одна цифра. Вот пример:
Nov 6 18:00:41 xmdoc smbd_audit: XS\kobelev|10.1.4.49|documents|open|ok|r|Конструкторы/_Проекты/15667/проработка.dwg
Nov 13 12:04:47 xmdoc smbd_audit: XS\ignatev|10.1.4.81|documents|open|ok|r|Конструкторы/_Проекты/02649.обрамление.dwg
В первом случае после Nov стоят 2 пробела. Это усложняет настройку парсинга. Поэтому лишние пробелы и символы убираем. После работы фильтра mutate мы получим вот такую строку:
Nov 6 18:00:41 xmdoc smbd_audit: XS:kobelev:10.1.4.49:documents:open:ok:r:Конструкторы/_Проекты/15667/проработка.dwg
Дальше вступает в дело фильтр grok и его правило обработки:
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}Оно не идеальное, но мои запросы удовлетворяет. Проверить работу фильтра можно в grok debugger. На выходе будет вот такой json:
{
"user_ip": "10.1.4.49",
"share_name": "documents",
"syslog_time": "18:00:41",
"srv_name": "xmdoc",
"user_name": "kobelev",
"syslog_month": "Nov",
"path": "r:Конструкторы/_Проекты/15667/проработка.dwg",
"syslog_day": "6",
"sucess": "ok",
"action": "open"
}В моем случае не парсится значение домена XS из лога, так как все делается в рамках одного домена, и я просто опустил это действие. Вам нужно подработать правило под свои реалии. Если у вас много доменов, добавьте отдельное поле для имени домена. Если это не нужно, просто поменяйте на свой домен. Из названия полей думаю и так понятно, что я сделал. Я выделил ключевые для меня значения, которые дальше буду использовать в графиках и дашбордах. Я не смог отдельно выделить путь файла без лишних символов в начале. Не помню точно, с чем конкретно это связано, но в целом, проблема в том, что лог сильно изменяется в зависимости от проводимой операции. Единым фильтром было трудно все охватить, пришлось бы разделять разные события на разные потоки и анализировать отдельно. Я посчитал, что это не имеет смысла.
Если у вас samba не в домене, то лог будет немного другой. Вот пример строки лога и моего grok фильтра для обработки. Исходный лог:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20|scans|realpath|ok|Отсканированные счета/2018/счет.pdf
После работы фильтра mutate:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20:scans:realpath:ok:Отсканированные счета/2018/счет.pdf
Дальше вступает в дело grok фильтр
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}И на выходе получаем обработанные данные:
{
"user_ip": "10.1.5.20",
"share_name": "scans",
"syslog_time": "11:40:54",
"srv_name": "xb-share",
"syslog_month": "Nov",
"path": "Отсканированные счета/2018/счет.pdf",
"syslog_day": "13",
"sucess": "ok",
"action": "realpath"
}Теперь эти данные надо передать в elasticsearch. Добавляем в конфиг output.conf строки:
else if [type] == "smb-audit" {
elasticsearch {
hosts => "localhost:9200"
index => "smb-audit-%{+YYYY.MM}"
}
}Обращаю внимание, что данными настройками я формирую месячные индексы, а не дневные. Если у вас большой объем данных за день и вы не планируете хранить данные за несколько месяцев, то разбивайте индексы на дни.
Если других правил у вас нет, то else уберите. После этого нужно перезапустить logstash и проверять через kibana поступление обработанных логов.
Дашборд в ELC Stack для логов samba
Я немного поразмышлял и собрал вот такой dashboard для логов samba.
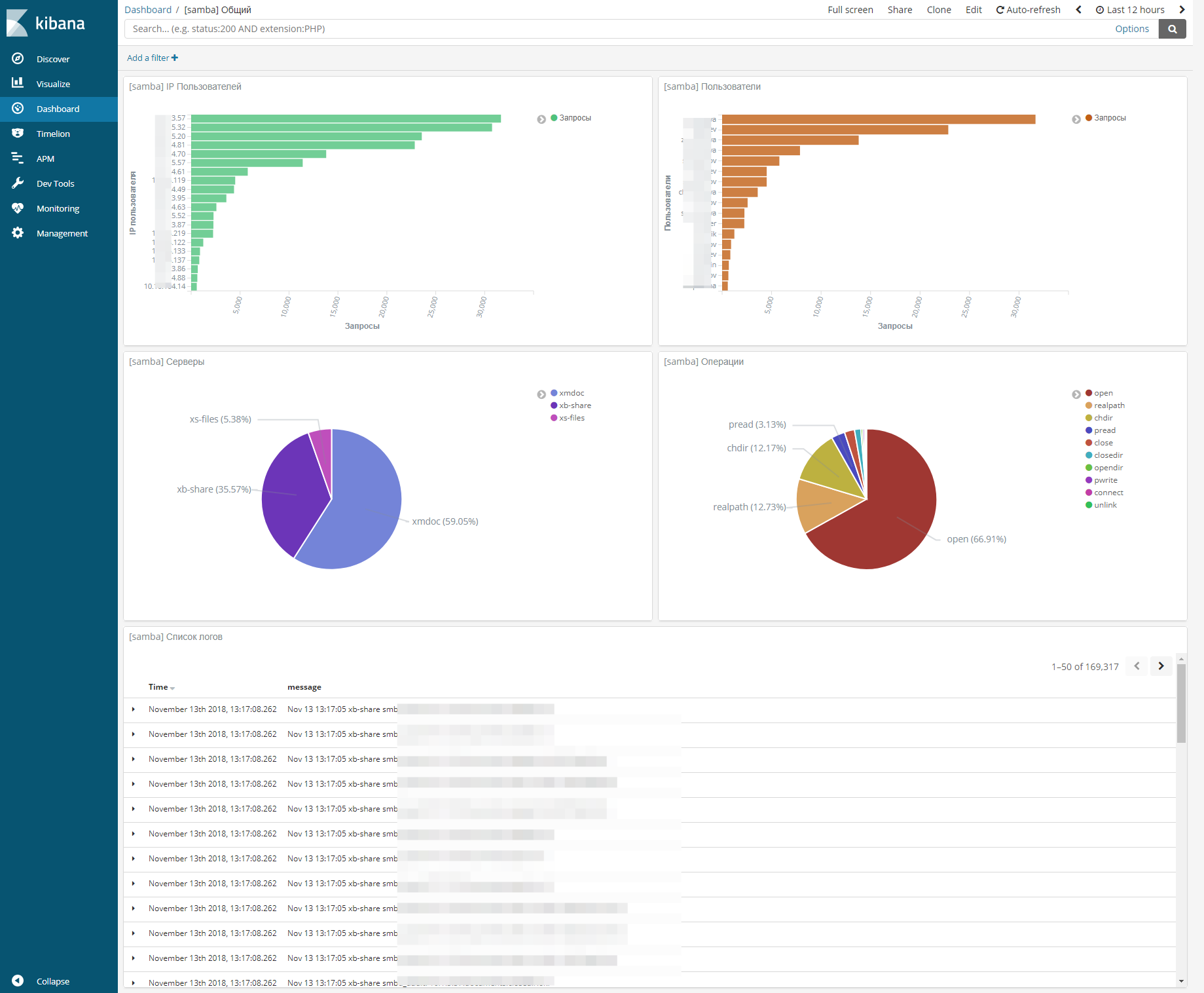
На этом дашборде расположены следующие визуализации:
- Количество запросов с конкретного IP.
- Количество запросов по доменному имени пользователя.
- Распределение запросов между тремя файловыми серверами.
- Распределение по типам операций.
- Список исходных логов.
При выборе конкретного сервера, мы получаем дашборд с информацией только по нему. То же самое по пользователям, ip, операциям и т.д. Стало ОЧЕНЬ удобно анализировать работу серверов. К примеру, если у вас в сети появится шифровальщик, вы сразу же это увидите на дашборде и узнаете ip источника проблемы. Про банальное — узнать, кто у удалил или изменил файл я и не говорю.
Большие выбросы на графиках дают пользователи, которые используют поиск по сетевым дискам. У них будет огромное количество операций чтения. Но тут уже ничего не поделать. Визуализация не идеальная, но тем не менее, очень упрощает жизнь.
Заключение
Вот таким относительно простым и эффективным способом можно облегчить управление файловыми серверами, особенно когда их много. Я раньше и представить не мог, что можно так удобно собрать всю информацию с логов и вывести в наглядном виде. А потом еще и фильтровать все это по нужным параметрам практически на лету.
В следующей статье расскажу, как сделать то же самое, только для файловых серверов на windows. Там примерно такой же dashboard будет, но сбор и анализ логов другие.


