Настройка мониторинга nginx, php-fpm, apache в Zabbix
Обновление моей старой и популярной статьи на тему мониторинга. В этой заметке мы займемся настройкой мониторинга web сервера nginx, apache и php-fpm в zabbix сервере с помощью готовых шаблонов. Полученная информация может пригодиться при анализе нагрузки на сайт, его скорости, при оценке качества хостинга, для прогнозирования максимально возможной посещаемости.
Я буду в своем примере настраивать все на CentOS 7, но в данном случае дистрибутив не имеет принципиального значения, все так же настраивается и на других linux системах с учетом их особенностей в установке пакетов и путей для конфигов и программ.
Мы будем использовать в качестве источника информации штатные возможности nginx, apache и php-fpm, затем передавать данные в zabbix сервер и там анализировать. Я подразумеваю, что nginx или apache вы уже настроили и имеете некое представление о работе его компонентов, поэтому некоторые вещи я не разжевываю, а просто говорю, что делать.
Подготовка nginx к мониторингу
Я планирую мониторить следующие параметры nginx:
| accepts per second | Число принятых соединений в секунду |
| active connections | Текущие активные соединения |
| handled per second | Число обработанных соединений в секунду |
| latency | Время ответа сервера в миллисекундах |
| memory allocated | Занимаемая память |
| process count | Число запущенных процессов |
| reading state connection count | Текущее число соединений, в которых nginx в настоящий момент читает заголовок запроса |
| requests per second | Число запросов в секунду |
| waiting state connection count | Текущее число бездействующих соединений в ожидании запроса |
| writing state connection count | Текущее число соединений, в которых nginx в настоящий момент отвечает |
| memory allocated | Сколько памяти занимают все worker process |
Сервер nginx умеет отдавать часть необходимой нам информации о своем состоянии. Для этого его надо соответствующим образом подготовить. Открываем конфиг сервера и добавляем туда следующую конструкцию:
server {
listen localhost;
server_name localhost;
keepalive_timeout 0;
allow 127.0.0.1;
allow ::1;
deny all;
access_log off;
location /nginx-status {
stub_status on;
}
Я обычно добавляю в самый конец основного конфига nginx.conf. Сохраняем и перечитываем конфигурацию, перед этим проверив его конфиг на ошибки:
# nginx -t # nginx -s reload
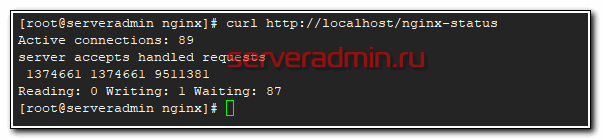
Проверяем, можем ли мы получить необходимую информацию для настройки мониторинга:
# curl http://localhost/nginx-status Active connections: 89 server accepts handled requests 1374661 1374661 9511381 Reading: 0 Writing: 1 Waiting: 87
Теперь проверим, сможет ли zabbix получать эту страницу.
# zabbix_agentd -t web.page.get[localhost,nginx-status,80]
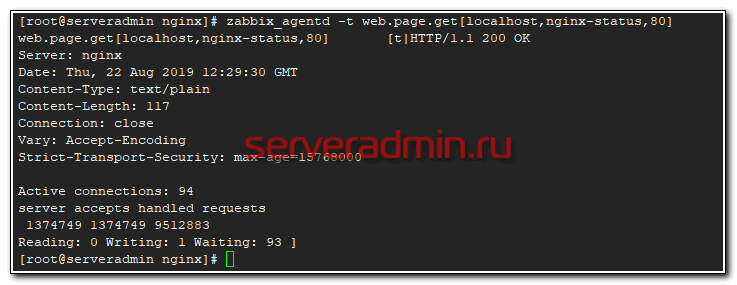
Если у вас так же, то все в порядке, можно двигаться дальше. Если что-то не получается, то проверяйте конфиги, смотрите логи. Это штатный функционал, он должен без проблем настраиваться и работать.
Сразу обращаю внимание на один важный момент, на котором я застрял на приличное время. Через curl я без проблем забирал страничку со статусом nginx, а вот через zabbix никак не получалось. Была ошибка:
[m|ZBX_NOTSUPPORTED] [HTTP get error: cannot connect to [[localhost]:80]: [111] Connection refused]
Я всю голову сломал, 10 раз перепроверил конфиги, никак не мог понять, почему не работает. Оказалось, дело было вот в чем. Zabbix-agent обращался к серверу Nginx по протоколу ipv6. Это при том, что как агент, так и nginx работали по ipv4. Я принудительно отключаю у служб ipv6, если он не используется.
Обнаружил это случайно, когда от безысходности запустил Nginx на всех интерфейсах и снял ограничения allow/deny в конфиге. Тогда запрос прошел нормально. Я посмотрел access лог и увидел, что zabbix-agent обращается с адреса ::1. И все стало ясно. Я так и не понял, как заставить агента ходить по ipv4. В итоге запустил nginx на обоих протоколах и разрешил забирать страницу статуса с адреса ::1. После этого заработало.
Самое неприятное в этой ситуации было то, что в логах нигде не было никаких ошибок, отклоненных запросов или чего-то еще, что могло бы дать зацепку. Zabbix agent просто писал, что подключение отклонено и все. О том, что он обращается по ipv6, не было никакого намека.
Настройка в zabbix мониторинга nginx
В прошлой редакции этой статьи дальше шло описание скрипта, который будет парсить вывод nginx-status и передавать данные в zabbix. Сейчас все можно сделать гораздо проще и удобнее. На агенте не надо ничего настраивать. Все выполняется исключительно в шаблоне. То есть вам достаточно загрузить готовый шаблон для мониторинга nginx на zabbix сервер, прикрепить его к хосту и все будет работать.
Это удобный подход, который избавляет от необходимости настраивать агентов. Теперь все выполняется с сервера. Минус этого подхода только в том, что возрастает нагрузка на сервер мониторинга. Это плата за удобство и централизацию. Имейте это ввиду. Если у вас большая инсталляция мониторинга и есть средства автоматизации типа ansible, возможно вам имеет смысл по старинке парсить данные скриптом. Но в общем случае я рекомендую делать так, как я расскажу далее.
Суть мониторинга Nginx будет сводиться к тому, что мы через агента станем забирать страницу http://localhost/nginx-status на сервер. Там с помощью регулярных выражений и зависимых элементов данных будем формировать нужные метрики.
Представляю вам готовый шаблон для мониторинга nginx. Скачиваем его zabbix-nginx-template.xml и открываем web интерфейс zabbix сервера. Идем в раздел Configuration -> Templates и жмем Import:
Выбираем файл и снова нажимаем Import:
Шаблон я подготовил сам на основе своих представлений о том, что нужно мониторить. Проверил и экспортировал его с версии 4.2 Регулярные выражения для парсинга html страницы статуса подсмотрел тут — https://github.com/AlexGluck/ZBX_NGINX. К представленному шаблону я добавил некоторые итемы и переделал все триггеры. Плюс убрал макросы. Не вижу в них в данном случае смысла.
В шаблоне 11 итемов, описание которых я привел ранее.
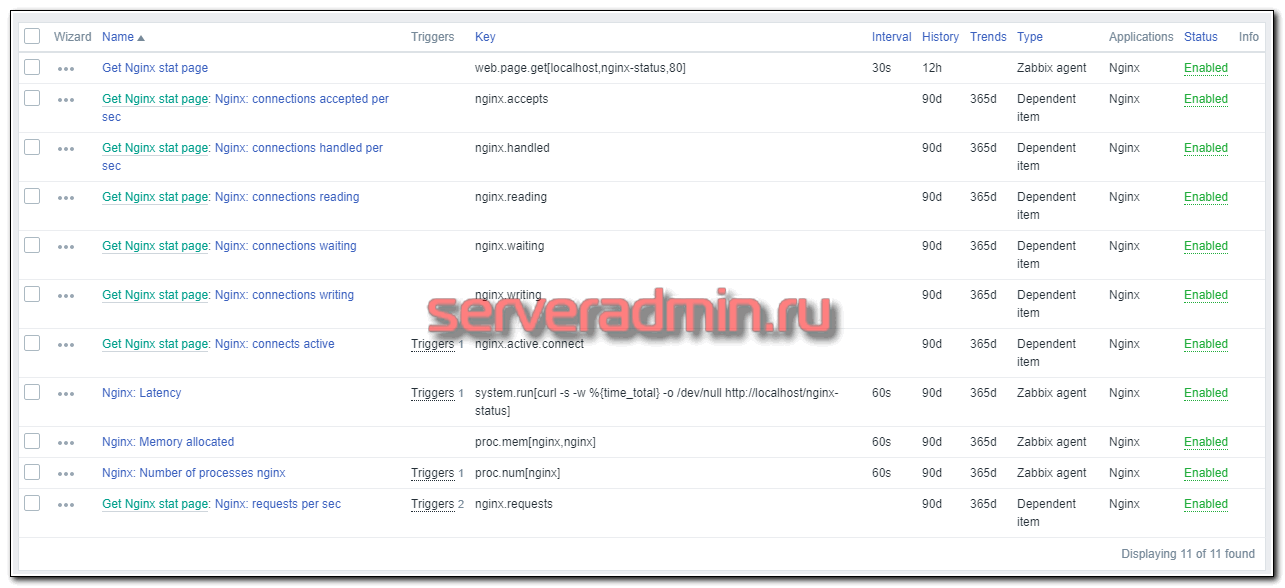
Подробнее остановимся на триггерах. Их 5 штук.

- Many active connections — срабатывает если среднее количество соединений за последние 10 минут больше в 3 раза, чем среднее количество за интервал на 10 минут ранее.
- many requests и too many requests — срабатывают, когда среднее количество запросов за последние 10 минут больше в 3 и 6 раз соответственно, чем на 10 минут ранее.
- nginx is not running — тут все просто. Если не запущен ни один процесс nginx, шлем уведомление.
- nginx is slow to respond — срабатывает если время выполнения запроса на получение страницы со статусом за последние 10 минут больше предыдущих 10 минут в 2 раза.
С триггерами больше всего вопросов. Предложенная мной схема может работать независимо от проекта, не требует начальной калибровки, но могут быть ложные срабатывания из-за разовых очень сильных всплесков, которые быстро проходят, но сильно меняют средние параметры на интервале.
Более надежно могут сработать триггеры, где явно указаны лимиты в конкретных значениях. Но такой подход требует ручной калибровки на каждом проекте в отдельности. Надо смотреть средние значения метрик и выставлять лимиты в зависимости от них. Если проект будет расти, то лимиты постоянно придется менять. Это тоже не очень удобно и не универсально.
Я в итоге остановился на анализе средних значений, не используя конкретных лимитов. Как поступать вам, решайте отдельно, в зависимости от ситуации. Если у вас один проект, которому вы уделяете много внимания, то ставьте лимиты руками на основе анализа средних параметров. Если работаете на потоке с множеством проектов, то можно использовать мой вариант, он более универсален и не требует ручной правки.
Единственное, коэффициенты можно поправить, если будут ложные срабатывания. Но я обычно этот момент решаю через отложенные уведомления. Если чувствительность триггера очень высокая и есть кратковременные ложные срабатывания, меня они не беспокоят из-за 5-ти минутной задержки уведомлений. Зато при разборе инцидентов, эти кратковременные срабатывания помогают оценить ситуацию в целом.
С мониторингом nginx почти все готово. Теперь нам нужно прицепить добавленный шаблон к web серверу, который мы мониторим и дождаться поступления данных. Проверить их можно в Monitoring -> Latest Data:
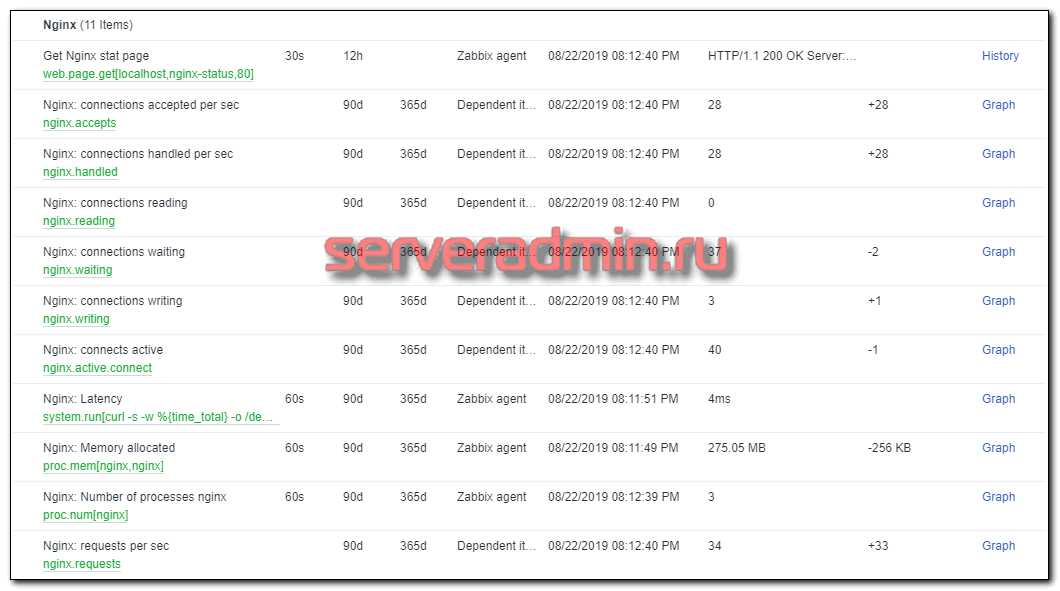
В шаблоне есть несколько графиков. Не буду о них рассказывать, так как последнее время практически не пользуюсь графиками. Вместо этого собираю дашборды. Это более удобно и информативно. Жаль, что дашборды нельзя к шаблонам прикреплять. Очень хлопотно каждый раз вручную их составлять и тратить время. В конце покажу пример дашборда, который я использую для мониторинга web сервера.
На этом настройка мониторинга nginx закончена, можно пользоваться.
Подготовка php-fpm к мониторингу
Переходим к мониторингу php-fpm. Он отдает побольше метрик, не буду описывать их все. Рассмотрю только самые основные. Мы будем наблюдать следующие параметры php-fpm:
| active processes count | Число активных процессов |
| connections per sec | Количество соединений в секунду |
| idle processes count | Количество idle процессов |
| slow requests | Количество медленных запросов |
| length of listen queue | Размер очереди ожидающих подключений |
| max children reached | Сколько раз был достигнут лимит по процессам |
| max length of listen queue | Максимальный размер очереди подключений |
Пару слов о том, зачем это нужно и как пользоваться полученными данными. Этот мониторинг актуален, если у вас динамическое создание процессов в php-fpm. К примеру, если у вас значение max children reached регулярно больше единицы, то вам рекомендуется увеличить лимит на максимальное количество процессов, если позволяют ресурсы сервера. То же самое относится и к параметру length of listen queue. Если он больше нуля, то создается очередь из запросов, которые не успевают обработать сервер. Необходимо увеличить количество процессов, которые смогут обработать ожидающие подключения.
Приступаем к настройке мониторинга php-fpm на web сервере. Установим fcgi:
# yum install fcgi
Теперь подготовим pfp-fpm для сбора статистики. Для этого мы снова воспользуемся nginx. Редактируем его конфиг, добавляя в ту же секцию server, что и на прошлом этапе, следующую конструкцию:
location /phpfpm-status {
include fastcgi_params;
fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}Обращаю ваше внимание на то, что я в своей конфигурации использую подключение к php-fpm через unix сокет. За это отвечает параметр конфигурации fastcgi_pass. Если вы используете в работе tcp/ip порт, обычно 127.0.0.1:9000, то нужно указать его вместо сокета, вот так: fastcgi_pass 127.0.0.1:9000
Перезапускаем nginx:
# systemctl restart nginx
Внесем необходимые изменения в конфиг php-fpm — добавим одну строку:
# mcedit /etc/php-fpm.d/www.conf pm.status_path = /phpfpm-status
Перезапускаем php-fpm:
# systemctl restart php-fpm
Проверяем, что по указанному адресу мы получаем статистику php-fpm:
# curl http://localhost/phpfpm-status
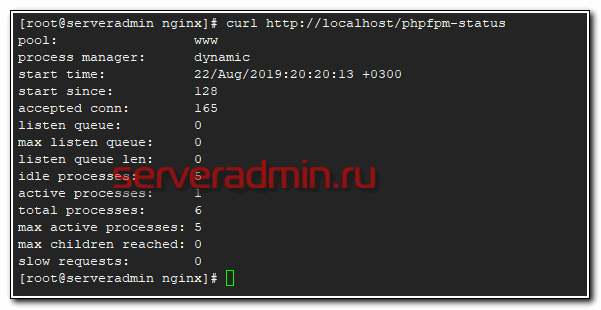
И ее же в формате json.
# curl -s 'http://localhost/phpfpm-status?json'
{"pool":"www","process manager":"dynamic","start time":1566494413,"start since":2049,"accepted conn":3236,"listen queue":0,"max listen queue":0,"listen queue len":0,"idle processes":5,"active processes":1,"total processes":6,"max active processes":6,"max children reached":0,"slow requests":0}Если у вас примерно то же самое, то все в порядке, php-fpm отдает информацию о своем состоянии.
Мониторинг php-fpm в zabbix
Теперь настраиваем мониторинг php-fpm на сервере zabbix. Действуем по аналогии с мониторингом nginx. Забираем страницу состояния php-fpm на сервер мониторинга и там его парсим в зависимых элементах данных.
С php-fpm будет один нюанс. Нам все-таки придется менять параметры zabbix agent. Настраивать мониторинг php-fpm очень легко, потому что он из коробки умеет отдавать все свои метрики в формате json. Это очень удобно, так как его не надо парсить регулярками. Достаточно только указать JSONpath для получения необходимой метрики.
Нам нужно добавить один UserParameter следующего содержания.
UserParameter=phpfpm.json[*],curl -s 'http://localhost/phpfpm-status?json' | tr ' ' _
Перезапускаем zabbix-agent и проверяем, что он корректно возвращает необходимые данные.
# systemctl restart zabbix-agent
# zabbix_agentd -t phpfpm.json
phpfpm.json [t|{"pool":"www","process_manager":"dynamic","start_time":1566494413,"start_since":3525,"accepted_conn":5820,"listen_queue":0,"max_listen_queue":0,"listen_queue_len":0,"idle_processes":6,"active_processes":1,"total_processes":7,"max_active_processes":7,"max_children_reached":0,"slow_requests":0}]Дальше как и в случае с nginx, идем в веб интерфейс и импортируем шаблон zabbix-phpfpm-template.xml. Добавляем этот шаблон к серверу и ждем обновления данных. Проверяем их поступление, как обычно, в Monitoring -> Latest Data:
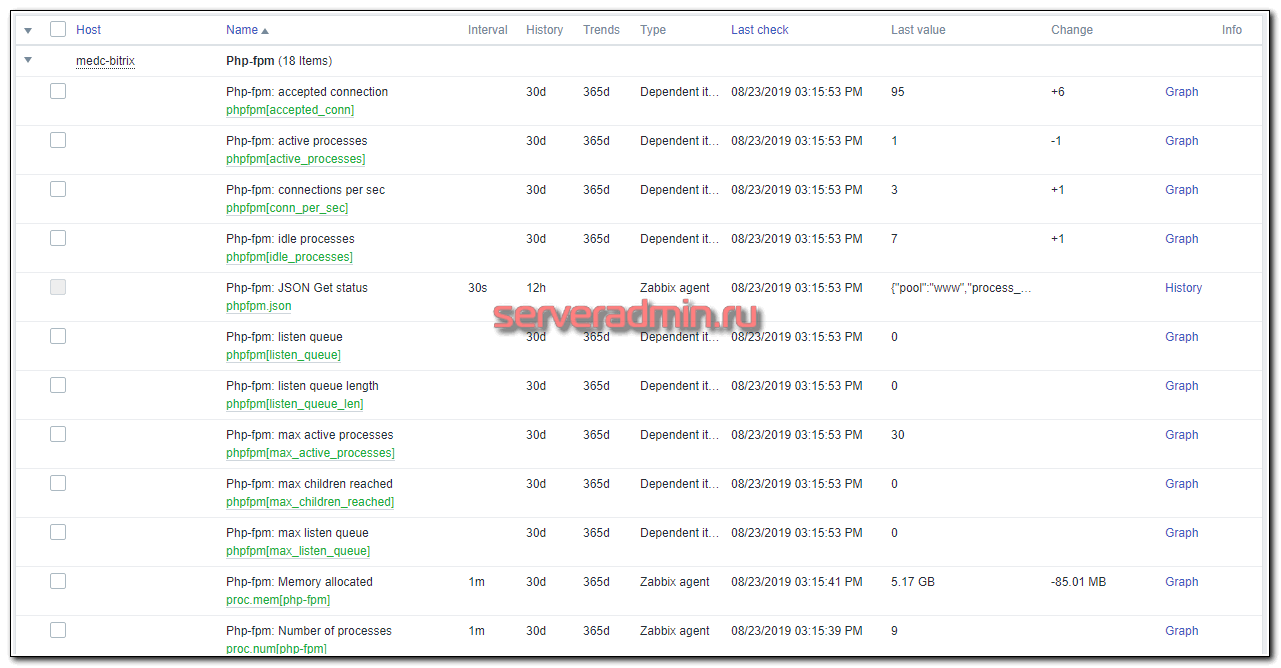
Если все в порядке, то проверяйте графики, создавайте необходимые дашборды. Я свой покажу в самом конце.
В шаблоне php-fpm настроен только один триггер, который следит за тем, чтобы хотя бы один процесс php-fpm был запущен. Раньше я использовал больше триггеров, но потом решил, что они не очень нужны. Состояние работы сайта лучше оценивать по финальным метрикам, таким как скорость загрузки страниц, доступность сайта и коды ответов. Если с этими метриками проблемы, нужно идти в мониторинг, смотреть графики и решать, что нужно изменить в конфигурации. Это мое личное мнение, с ним можно поспорить. Для этого есть комментарии, буду рад замечаниям и обсуждениям по существу.
Подготовка apache к мониторингу
Приступим к настройке мониторинга web сервера apache. В данном примере я буду использовать web сервер для сайта на bitrix, работающего в окружении bitrixenv. В целом, тут никаких принципиальных отличий нет от обычного apache, просто представлена готовая конфигурация с обширными настройками.
С веб сервером apache мне давно не приходилось связываться в отрыве от bitrix сайтов, поэтому решил показать его мониторинг на его примере. Здесь принцип будет такой же, как и раньше — забираем страницу с информацией о веб сервере, который apache нам предоставляет через свой модуль mod_status.
Дальше мы передаем страницу в zabbix server и там парсим регулярками по зависимым элементам данных. Первым делом вам надо настроить указанный выше модуль. Подробности на официальном сайта — https://httpd.apache.org/docs/current/mod/mod_status.html. Если кратко, то просто добавьте в конфиг apache примерно следующие настройки.
<Location "/server-status">
SetHandler server-status
Require host localhost
</Location>Bitrixenv автоматически все настроит, если вы через консольное меню включите Monitoring in pool. Запустится роль ansible, которая настроит в том числе apache, установит и запустит nagios и munin. Если они вам не нужны, то просто добавьте приведенный выше кусок конфига в /etc/httpd/bx/custom/z_bx_custom.conf.
Listen localhost:8886
<IfModule mod_status.c>
ExtendedStatus On
</IfModule>
<VirtualHost localhost:8886>
<Location /server-status>
SetHandler server-status
Require ip 127.0.0.1
require ip ::1
</Location>
</VirtualHost>
После этого проверьте настройки apache и перезапустите его.
# apachectl -t # apachectl restart
Если все настроили правильно, то состояние apache можно посмотреть в консоли.
# curl http://localhost:8886/server-status?auto Total Accesses: 1051 Total kBytes: 104324 CPULoad: 4.7515 Uptime: 1835 ReqPerSec: .572752 BytesPerSec: 58216.8 BytesPerReq: 101644 BusyWorkers: 1 IdleWorkers: 29 Scoreboard: _______________________W______
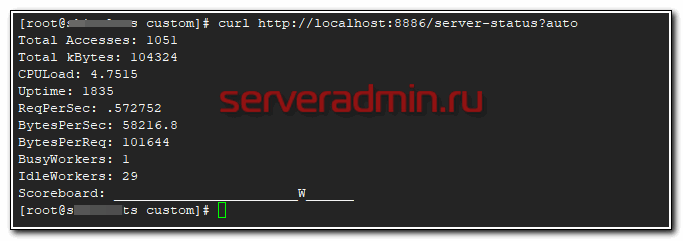
И на всякий случай проверьте, что zabbix-agent может получать эту же информацию.
# zabbix_agentd -t web.page.get[localhost,server-status?auto,8886]
Должны увидеть то же самое, только со служебными заголовками в начале. Если у вас все в порядке, то можно двигаться дальше.
Настройка мониторинга apache
Теперь настроим мониторинг apache в zabbix server. Как обычно, я подготовил шаблон с итемами и триггерами, которые посчитал полезными. Скачиваем его — zabbix-apache-template.xml.
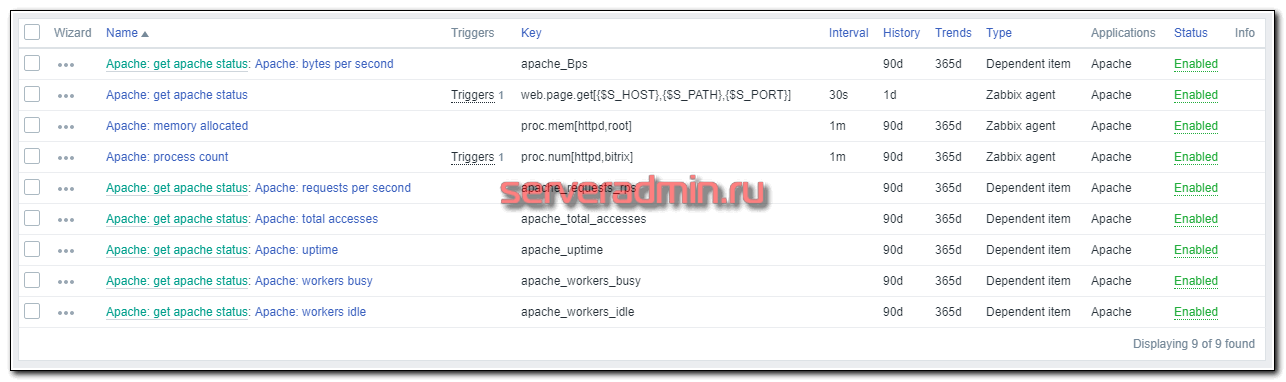
Обратите внимание на элемент, который забирает страницу со статусом. Его url я реализовал через макросы:
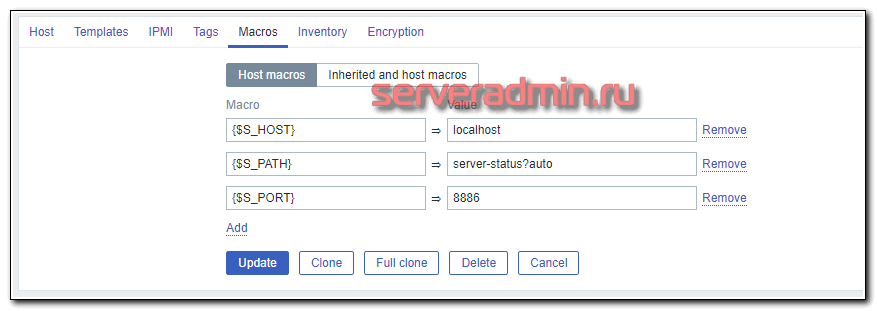
- {$S_HOST} — название виртуального хоста
- {$S_PATH} — путь к странице со статистикой
- {$S_PORT} — порт сервера apache, на котором работает статистика
Вот как выглядят настройки макроса на типичном сайте с bitrixenv.
Так же обращаю внимание на итемы проверки количества рабочих процессов и занимаемой виртуальной памяти. Для проверки процессов указан пользователь bitrix, от которого работают все воркеры. В случае проверки памяти указан пользователь root, так как основной процесс запущен от него. А все воркеры используют разделяемую память. Ее суммарный объем, особенно когда воркеров много, огромен и представляет из себя нереальную цифру. Отслеживать ее нет никакого смысла.
Так как apache обычно работает в роле бэкенда, у него минимум триггеров, как и у php-fpm. Я сделал 2:
- Apache service not work — предупреждение о том, что системный процесс web сервера apache не запущен.
- Failed to fetch apache server status page — триггер срабатывает, если не получается загрузить страницу со статистикой.
Добавил еще пару графиков. Сами на них посмотрите. Вот в общем-то и все. После настройки шаблона для мониторинга apache, прикрепите его к хосту, не забудьте указать макросы и ждите поступления данных.
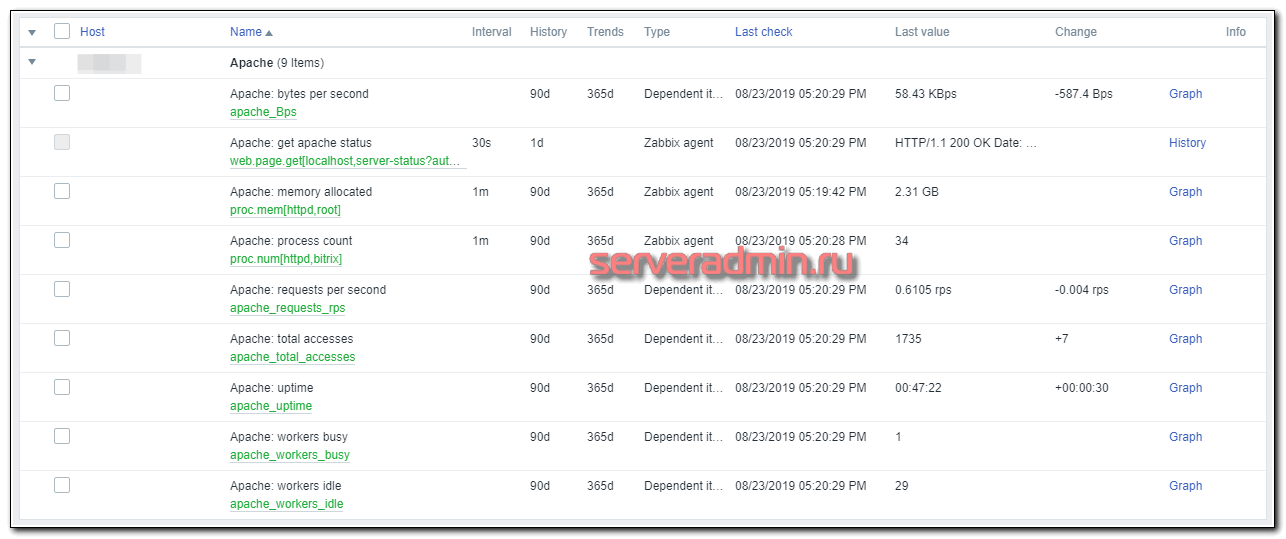
На это про мониторинг apache в zabbix все. Дальше идет пример готового Dashboard.
Дашборд Zabbix для Web сервера
Как и обещал, в завершении статьи по настройке мониторинга web сервера, показываю пример своего дашборда в zabbix для мониторинга bitrix сайта. Картинка очень большая, по клику открывается полная версия, если открыть в новой вкладке.
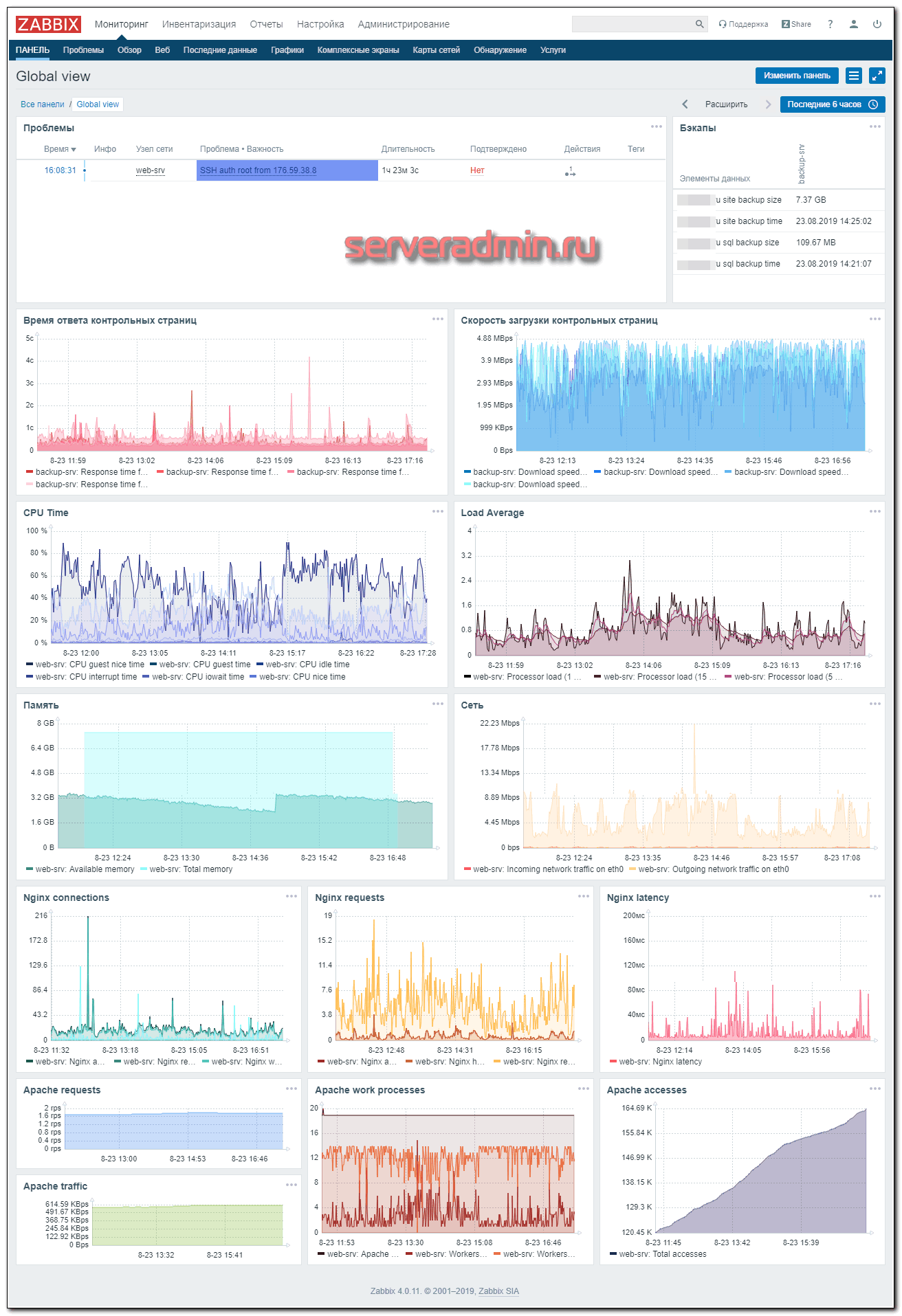
В самом верху список текущих проблем. В настоящий момент висит активный триггер о ssh подключению к серверу. Справа от списка проблем — мониторинг бэкапов в zabbix.
Рекомендую сделать обе настройки. Первая очень помогает понимать, что происходит с сайтом и сервером, если с ним работают несколько человек. Если разработчик залез на сервер по ssh — жди беды. С бэкапами и так все понятно — без них никуда. Возможно как-нибудь отдельно напишу, как я бэкаплю сайты, чтобы защищаться от различного рода угроз и быстро восстанавливать функционирование сайта после сбоев. Просто скопировать весь сайт в другое место недостаточно, особенно если он очень большой. Нужен отдельный продуманный подход к этому вопросу. Напишите в комментариях, если вам интересно получить эту информацию.
Ниже идут метрики с мониторинга web сайта. Выбирается контрольный набор из нескольких страниц (обычно 3-5) и настраивается мониторинг времени ответа и скорости загрузки этих страниц. Для этих параметров настроены триггеры, так как они очень важны. По сути, это ключевые метрики. Если с ними проблемы, надо внимательно смотреть web сервер и разбираться, в чем проблема. Мониторинг web сайта нужно настраивать минимум с двух независимых серверов zabbix, иначе вы не сможете отличить проблемы доступа с сервера мониторинга к сайту от реальных проблем сайта. Только если оба сервера мониторинга сигнализируют о проблемах, можно сделать однозначный вывод о том, что с сайтом и web сервером что-то не так.
Дальше идут метрики из шаблонов, которые я рассмотрел в этой статье. Если у вас вместо apache используется php-fpm, то все примерно то же самое, только в самом низу метрики от php-fpm. Не буду приводить пример с ним, чтобы не загромождать статью. Думаю, приведенного дашборда и так достаточно.
В принципе, сюда можно было бы добавить информацию по I/O дисков, инфу с сетевого стека, данные Mysql. Не стал этого делать, так как это обзорный dashboard, который беглым просмотром позволяет оценить состояние сервера. Так же этот дашборд можно показать заказчику. Для более глубокого анализа проблем, нужно собирать отдельную панель.
Заключение
Подведем итог того, что мы сделали:
- Настроили сервисы nginx, apache, php-fpm таким образом, чтобы они отдавали информацию о своем состоянии.
- С помощью zabbix агентов передали эту информацию на сервер.
- Используя зависимые элементы (dependent items) настроили парсинг метрик.
- Настроили на сервере мониторинга необходимые шаблоны и прикрепили их к наблюдаемым серверам.
- Собрали dashboard для мониторинга за веб сервером.
То есть выполнили весь комплекс действий для организации полноценного мониторинга web сервера в zabbix.
Одно из применений подобного мониторинга — выбор более быстрого хостинга для сайта. К примеру, мне некоторое время назад понадобилось сменить хостинг. Но как узнать, будет ли он быстрее текущего или нет. Характеристики примерно у всех одинаковые. Я просто взял тестовый период, настроил на сервере все, что мне нужно, в том числе мониторинг веб сервера, перенес туда сайт и понаблюдал сутки. Уже по времени отклика nginx и php-fpm мне стало понятно, что новый хостинг быстрее:
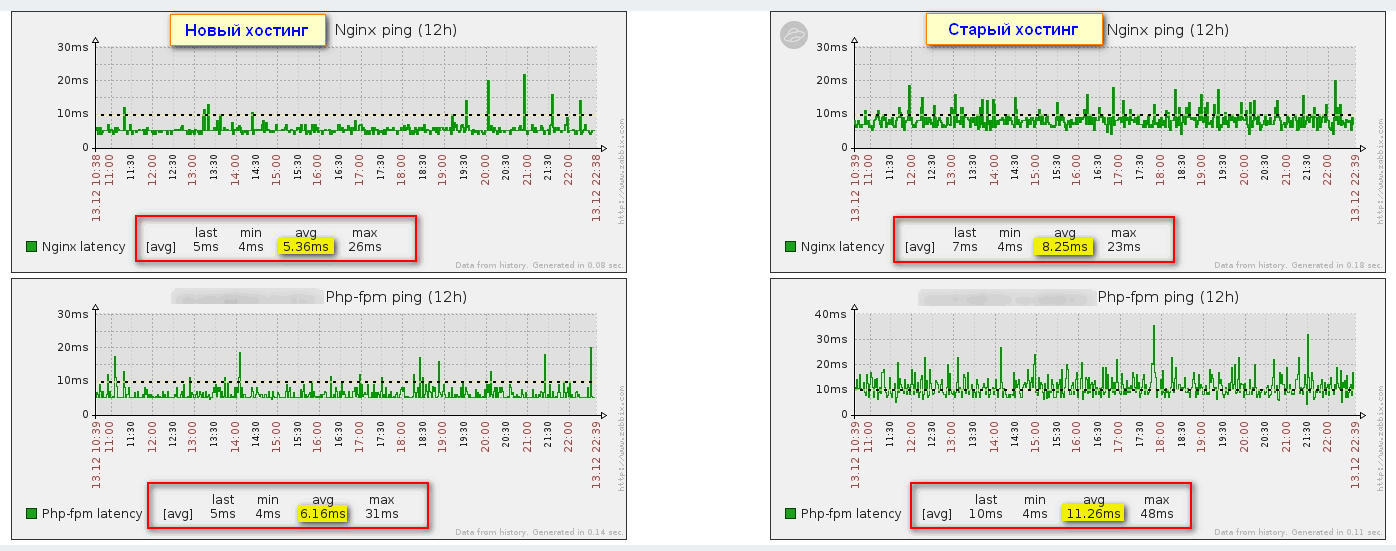
Время отклика страниц сайта и скорость их загрузки в целом тоже улучшились. Я однозначно понял, что надо переезжать и не ошибся.
Это пример из старой версии статьи, где показаны старые метрики и графики. Оставил его, так как он в целом информативен. Текущий мониторинг web сайта так же можно использовать для анализа производительности хостинга.
