Мониторинг размера бэкапа в Zabbix
Ранее я уже рассказывал, как мониторить бэкапы с помощью zabbix. Захотелось собирать информацию о размере бэкапа, чтобы смотреть тренды по его увеличению или уменьшению. Немного пораскинул мозгами и придумал решение задачи по мониторингу размера бэкапов с помощью уже привычного инструмента UserParameter.
Введение
Я уже много раз использовал внешние скрипты и UserParameter для мониторинга в zabbix. Не буду подробно на этом останавливаться. Приведу список своих материалов по этой теме:
- Мониторинг информации из текстовых файлов
- Следим за временем делегирования домена в zabbix
- Мониторинг бэкапов
- Статус транков в астериск
- Мониторинг рейда mdadm
- Наблюдение за mysql репликацией с помощью заббикс
- Состояние веб сервера nginx и php-fpm
- Мониторинг температуры windows сервера
Использовать будем такой же подход. У нас будет 2 скрипта. Первый будет собирать информацию о размерах папок с файлами, второй будет передавать сформированные данные в заббикс. Делать все будем раз в сутки, чаще нет смысла, так как у меня бэкапы выполняются с суточным интервалом. Сами бэкапы представляют из себя не отдельные файлы-архивы, а папки. Настроено все примерно так же, как в статье про настройку backup с помощью rsync.
Скрипты по сбору информации о размере бэкапов
Первый скрипт будет проверять размер каталогов и записывать результат в текстовый файл. Сначала я собирал размер в байтах, потом решил скриптом преобразовывать в гигабайты, но через некоторое время нашел способ в заббиксе преобразовывать размер из байтов в гигабайты и снова стал в заббикс передавать только байты. Так оказалось удобнее всего. Создаем папку для скриптов и кладем туда сам скрипт:
# mkdir /etc/zabbix/scripts # mcedit /etc/zabbix/scripts/size-backup-dir.sh
#!/bin/bash
# Файл с информацией о размере папок
logfile=/etc/zabbix/scripts/size-log.txt
# Удаляем файл предыдущей работы скрипта
rm $logfile
# Определяем размер папки
size_1c=`du -s /mnt/data/backup/1c | awk '{print $1}'`
# Записываем результат в текстовый файл
echo 1c $size_1c >> $logfileЕсли у вас несколько папок с бэкапами, добавляете их все в скрипт. Можно автоматизировать этот процесс, задать переменные с названиями папок с бэкапами и в цикле их перебирать, но у меня это не получилось, так как пути сильно разные. Пришлось все в ручную добавлять. Я привожу пример с одной папкой. Остальные по аналогии добавляете, не забывая изменять имена переменных, в которые передается размер директории.
Результатом работы скрипта будет файл следующего содержания:
# cat size-log.txt 1c 41374052
| 1с | имя бэкапа |
| 41374052 | размер бэкапа в байтах |
Необходимо добавить этот скрипт в крон и выполнять раз в сутки. Находите конфиг крона в вашей системе и добавляете туда:
30 15 * * * /etc/zabbix/scripts/size-backup-dir.sh
Время выбираете на свое усмотрение. В данном случае у меня отдельный сервер для бэкапов, его можно днем напрячь, когда он простаивает.
Дальше рисуем скрипт, который будет передавать данные в заббикс:
# mcedit /etc/zabbix/scripts/send-zabbix-size.sh
#!/bin/bash cat /etc/zabbix/scripts/size-log.txt | grep $1 | cut -d " " -f 2
Проверяем его работу следующим образом:
# ./send-zabbix-size.sh 1c 41374052
На выходе просто цифра с размером, которая уходит на сервер заббикса. То, что нужно. Важно не забыть один момент, иначе ничего не зааработает. Скрипту нужно назначить владельца zabbix, чтобы агент мог его запускать:
# chown zabbix. /etc/zabbix/scripts/send-zabbix-size.sh
Если этого не сделать, получите ошибку в логе агента:
sh: 1: /etc/zabbix/scripts/send-zabbix-size.sh: Permission denied
Настраиваем zabbix агент
Делаем все как обычно. Идем в папку /etc/zabbix/zabbix_agentd.conf.d и создаем файл с пользовательскими параметрами:
# mcedit /etc/zabbix/zabbix_agentd.conf.d/backup-size.conf
UserParameter=size.1c,/etc/zabbix/scripts/send-zabbix-size.sh 1c
Сохраняем файл. Перезапускаем агента и проверяем в консоли, что улетит на сервер:
# zabbix_agentd -t size.1c size.1c [t|41374052]
Все в порядке, агент настроили. Осталось добавить новый итем на сервер.
Добавляем новый итем на сервер мониторинга zabbix
Кратко расскажу, что делать на сервере. Раньше я уже неоднократно рассматривал этот момент, поэтому не буду на нем подробно останавливаться. Больше информации можете получить в предыдущих статьях, которые я привел в самом начале. Идем в веб интерфейс. Выбираем хост, на котором мы только что настраивали агент, заходим в список итемов и добавляем новый:
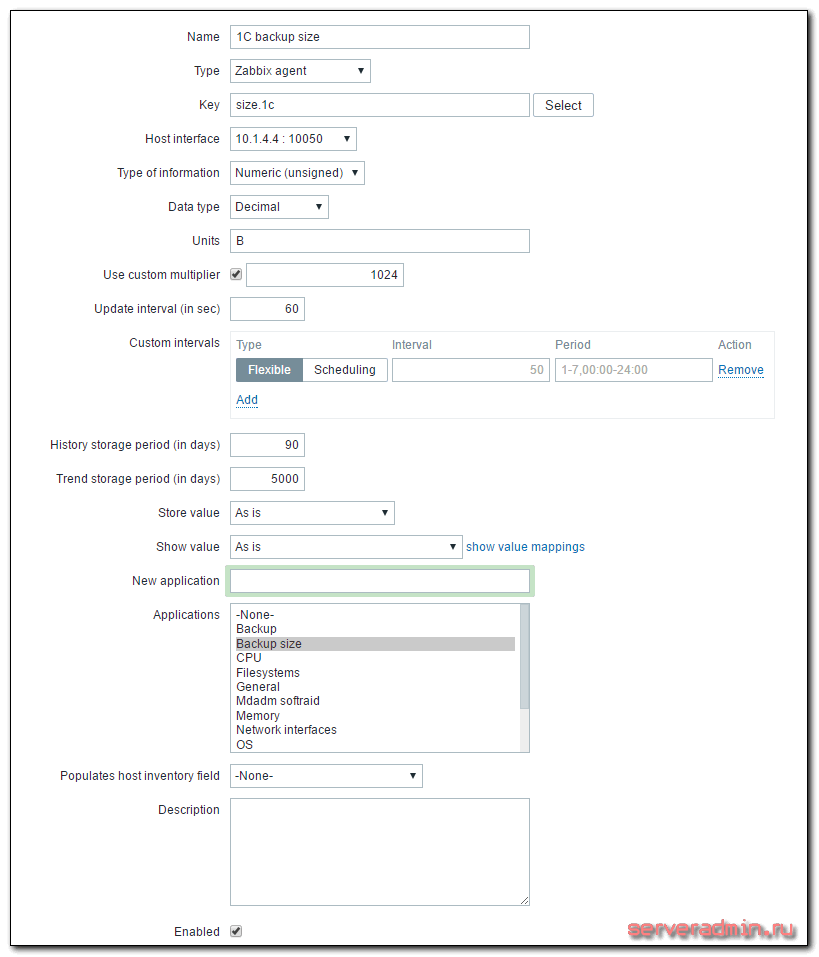
| Name | Произвольное имя итема. |
| Key | Название ключа, должно быть точно таким же, как в UserParameter в агенте. |
| Update interval | Время обновления, в данном случае раз в минуту для отладки, потом рекомендую ставить раз в сутки. |
| Units | Единица измерения, в данном случае байты. |
| Use custom multiplier | Пользовательский множитель для корректного перевода в гигабайты |
Сохраняем новый итем и ждем поступления данных. В случае указания большого интервала обновления, к примеру, раз в сутки, я не знаю, когда заббикс первый раз проведет опрос. Будет здорово, если кто-нибудь подскажет. Меня всегда интересовал этот момент. Во время отладки я ставлю маленький интервал обновления, например минуту или две. После того, как убеждаюсь, что все работает корректно, изменяют интервал на необходимый.
Смотреть результат следует, как обычно, в Latest data. Там же можно и график посмотреть, когда накопятся данные для него. Для более наглядных и красивых графиков, необходимо будет их вручную создать в конструкторе графиков конкретного хоста. Лично мне достатчно информации из последних данных.

Заключение
С помощью внешних скриптов настроили еще один тип мониторинга для бэкапов. Если у кого-то есть мысли на тему того, что нужно мониторить у резервных копий, высказывайте пожелания, попробую реализовать. Я очень внимательно отношусь к бэкапам и помимо автоматических проверок стараюсь время от времени заходить и глазами проверять все ли в порядке, на месте ли данные и можно ли их восстановить.
На своем опыте убедился в необходимости таких проверок. Приходилось сталкиваться с отказами различных систем, в том числе и коммерческих. Сервис может тупо зависнуть или выключиться, а ты надеешься на оповещения об ошибках, а раз не получаешь их, думаешь, что все в порядке, а на самом деле у тебя нет резервных копий. Еще вариант, с которым приходилось сталкиваться, это когда вроде все в порядке, никаких ошибок нет, а во время восстановления получаешь ошибку чтения данных.
Было бы неплохо автоматизировать восстановление данных и сравнение их с оригиналом для стопроцентной уверенности в том, что у тебя живые копии. Но для этого нужны дополнительные ресурсы.

